前言
這次的 NMIXX 歌詞翻譯想要多放”羅馬拼音”、“中、“日”、“英”四個語言
想要藉由 LLM 一次翻譯完畢
但發現整筆 json 直接丟給 LLM 的品質不佳
為了解決一次性輸入大量資料
決定改由 N 8 N 來處理切片翻譯
除了自行建立 workflow 處理外
這次也有嘗試使用 agent mode 去處理 (IDE, CLI 都行),效果也是不錯的
但 N 8 N 來處理可以讓輸出格式更加穩定
Workflow
輸入->資料前處理 (切 batch) -> 送 LLM -> 資料後處理 (合併資料) -> 存 Google Drive
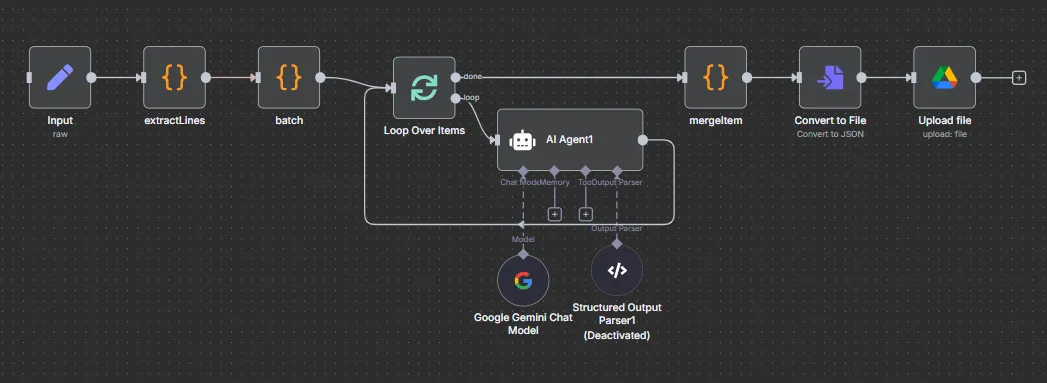
資料結構
在設計系統時
有把歌曲 import/export to json 做出來
使得要透過 LLVM 處理這些資訊輕鬆很多
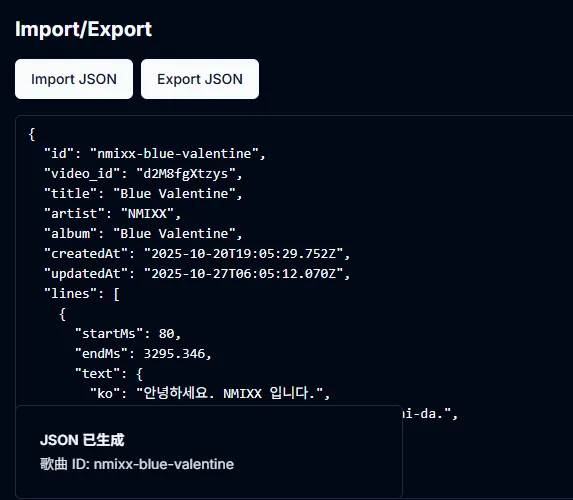
{
"id": "nmixx-home",
"video_id": "WY9DAofy0QI",
"title": "HOME",
"artist": "NMIXX",
"album": "expérgo",
"createdAt": "2025-10-18T22:14:19.296Z",
"updatedAt": "2025-10-19T17:37:21.805Z",
"lines": [
{
"startMs": 5410,
"endMs": 11690,
"text": {
"ko": "끝을 알리는 sirens 잠시 멈춰 (Yuh)"
},
"id": "line-1"
},
...
],
"annotations": [],
"meta": {
"durationMs": 164000,
"langs": [
"ko",
"romaji",
"en",
"ja",
"zh-Hant"
]
}
}
資料前處理
這邊要做的很簡單
就是把歌詞部分從 json 提出
切成多個片段
透過片段翻譯,減少幻覺,提升翻譯品質
因為翻譯不需要太強大的模型能力,這裡是使用 Gemini flash 模型,
AI Agent
這邊有做的是提供 system prompt + Structured Output Parser
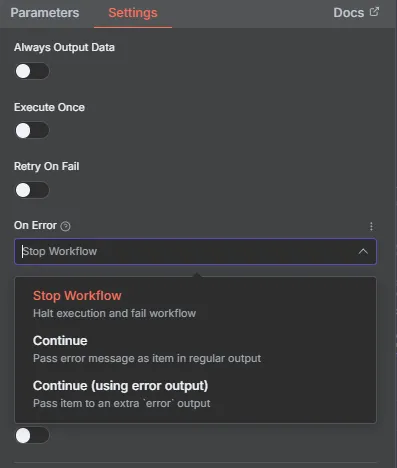
這裡有待優化的地方
偶爾會出現 format Error 導致翻譯鏈中止
看設定還有很多地方可以避免錯誤
SYSTEM PROMPT
你將收到一個完整的 JSON 物件,結構如下:
{json tamplate}
請嚴格遵守以下規則:
1. **翻譯來源:**
只處理每一行中的 `lines.<index>.text.ko`(韓文欄位)。
* 若 `ko` 欄含英文或專有名詞,需合理保留或音譯。
* 不改動其他欄位(例如:`id`、`時間戳`、`meta` 等)。
2. **輸出內容:**
在原 JSON 結構內填入以下四種翻譯結果:
* `romaji`: 韓文羅馬拼音,以 **常見羅馬化規則**。
* 單字間用 **`-`** 分隔,例如 `안녕하세요` → `an-nyeong-ha-se-yo`。
* `zh-Hant`: 自然口語的繁體中文翻譯。
* `en`: 自然英文翻譯。
* `ja`: 自然日文翻譯。
* 若行中含英文,英文部分原樣保留(但整行仍需完整轉寫)。
3. **格式要求:**
* 保留 `\n`,避免多餘空白或尾端無意義換行。
* 不新增或刪除任何鍵;所有語言鍵都必須存在,即使為空字串。
* 輸出結構必須與輸入完全一致,只更新翻譯欄位內容。
* 不得輸出解釋、附註或其他文字,只輸出 JSON。
4. **專有名詞固定翻譯對照:**
| ko | 翻譯(各語言中一致使用) |
| --- | ------------ |
| 엔믹스 | NMIXX |
| 엔써 | NSWER |
| 릴리 | Lily |
| 해원 | Haewon |
| 설윤 | Sullyoon |
| 배이 | Bae |
| 지우 | Jiwoo |
| 규진 | Kyujin |
5. **最終輸出格式:**
請直接輸出完整 JSON,**不加任何解說或包裝**。
Structured Output Parser
{
"batch": [
{
"startMs": 230.352,
"endMs": 1151.224,
"text": {
"ko": "안녕하세요.",
"romaji": "annyeonghaseyo.",
"zh-Hant": "大家好。",
"en": "Hello.",
"ja": "こんにちは。"
},
"id": "line-1"
}
]
}
資料後處理
合併多組資料
存入 Google Drive
就能透過 import json 匯入編輯模式了